{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/data/attach/topic/20240114/1705175126947_0.jpg', '推荐 acad2018 的文章《PPASR中文语音识别(入门级)》','http://wen.520xy8.com/article-4010.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
PPASR语音识别(入门级)
该项目将分为三个阶段,即入门级、优级和应用级分支。 目前它是入门级的。 随着级别的提高PPASR中文语音识别(入门级),识别准确率也会提高,更加适合实际项目使用。 敬请期待。 !
PPASR基于PaddlePaddle2实现的端到端自动语音识别。 这个项目头家的特点就是简单。 在保证准确率不低的同时英语识别语音,项目尽量做到简单易懂,让每一个想要入门语音识别的开发都能轻松上手。 PPASR仅使用卷积神经网络,没有其他特殊的网络结构。 该模型简单易懂,而且是端到端的。 不需要音频对齐,因为该项目使用 CTC Loss 作为损失函数。 在传统的语音识别模型中,在训练语音模型之前,文本和语音通常是严格对齐的。 在传统的语音识别模型中,在训练语音模型之前,我们往往必须严格对齐文本和语音。 这种对齐非常耗时英语识别语音英语识别语音,并且对齐后,模型预测的标签仅被部分分类。 从而无法给出整个序列的输出结果。 往往需要对预测的标签进行一些后处理学英语,才能得到我们想要的最终结果。 基于这种情况,CTC(联结主义时间分类)出现了。 使用 CTC Loss 不需要音频对齐。 直接输入是完整的句子语音数据,输出是整个序列结果。 在这种情况下,OCR 也是如此。
为了便于数据预处理,该项目主要使用梅尔频率倒谱系数(MFCC)对音频进行处理,然后使用得到的数据进行训练。 读取音频时,使用 librosa.load(wav_path, sr=16000) 函数读取音频文件,然后使用 librosa.feature.mfcc() 进行数据处理。 MFCC 代表梅尔频率倒谱系数。 Mel频率是根据人耳的听觉特性提出的,它与Hz频率具有非线性对应关系。 梅尔频率倒谱系数(MFCC)利用它们之间的这种关系来计算Hz频谱特征。 主要计算方法有预加重、分帧、加窗、快速傅里叶变换(FFT)、梅尔滤波器组、离散余弦变换(DCT),头家提取语音数据特征并降低计算维数。 该项目中使用的所有音频的采样率为16000Hz。 如果其他采样率的音频需要转换为16000Hz英语,create_manifest.py程序也提供了将音频转换为16000Hz的功能。
本项目的Github:入门级
在线运行
项目:
安装环境
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/复制
数据准备是下载公共数据集并在数据目录中制作训练数据列表和字典。 本项目提供公共汉语普通话语音数据集的下载,包括Aishell、Free ST-Chinese-Mandarin-Corpus、THCHS-30。 这三个数据集的总大小超过28G。 下载这三个数据只需要执行代码即可。 当然,如果你想快速训练,也可以只下载其中之一。
python3 data/aishell.py
python3 data/free_st_chinese_mandarin_corpus.py
python3 data/thchs_30.py复制
dataset/audio/wav/0175/H017优级0171.wav 我需要把空调温度调到二十度
dataset/audio/wav/0175/H017优级0377.wav 出彩中国人
dataset/audio/wav/0175/H017优级0470.wav 据克而瑞研究中心监测
dataset/audio/wav/0175/H017优级0180.wav 把温度加大到十八复制
python3 create_manifest.py复制
下面说说这些文件和数据的具体作用。 创建数据列表是为了在训练期间读取数据。 数据读取程序通过读取图像列表的每一行,可以获得音频文件路径、音频长度以及这句话。 内容。 通过路径读取音频文件并进行预处理。 音频长度用于统计数据的总长度。 文本内容是输入数据的标签。 训练时需要一个数据字典将文本内容转置为整数英语识别语音,比如这个词在数据字典中排第5位,那么它的标签就是4,标签是从0开始的。至于最终生成的均值和标准值,因为我们的数据在训练之前需要进行归一化处理,因为每个数据的分布是不同的,不同图像的头家值和最小值是确定的,所以我们需要统计一批数据。 计算平均值和标准值,并使用这些平均值和标准值进行后续数据归一化。
输出如下:
----------- Configuration Arguments -----------
annotation_path: dataset/annotation/
count_threshold: 0
is_change_frame_rate: True
manifest_path: dataset/manifest.train
manifest_prefix: dataset/
max_duration: 20
min_duration: 0
vocab_path: dataset/zh_vocab.json
------------------------------------------------
开始生成数据列表...
100|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 141600/141600 [00:17<00:00, 8321.22it/s]
完成生成数据列表,数据集总长度为178.97小时!
开始生成数据字典...
100|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 140184/140184 [00:01<00:00, 89476.12it/s]
数据字典生成完成!
开始抽取1%的数据计算均值和标准值...
100|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 140184/140184 [01:33<00:00, 1507.15it/s]
【特别重要】:均值:-3.146301, 标准值:52.998405, 请根据这两个值修改训练参数!复制
您可以使用 python create_manifest.py --help 命令查看各个参数的说明和默认值。
usage: create_manifest.py [-h] [----annotation_path ANNOTATION_PATH]
[--manifest_prefix MANIFEST_PREFIX]
[--is_change_frame_rate IS_CHANGE_FRAME_RATE]
[--min_duration MIN_DURATION]
[--max_duration MAX_DURATION]
[--count_threshold COUNT_THRESHOLD]
[--vocab_path VOCAB_PATH]
[--manifest_path MANIFEST_PATH]
optional arguments:
-h, --help show this help message and exit
----annotation_path ANNOTATION_PATH
标注文件的路径 默认: dataset/annotation/.
--manifest_prefix MANIFEST_PREFIX
训练数据清单,包括音频路径和标注信息 默认: dataset/.
--is_change_frame_rate IS_CHANGE_FRAME_RATE
是否统一改变音频为16000Hz,这会消耗大量的时间 默认: True.
--min_duration MIN_DURATION
过滤最短的音频长度 默认: 0.
--max_duration MAX_DURATION
过滤最长的音频长度,当为-1的时候不限制长度 默认: 20.
--count_threshold COUNT_THRESHOLD
字符计数的截断阈值,0为不做限制 默认: 0.
--vocab_path VOCAB_PATH
生成的数据字典文件 默认: dataset/zh_vocab.json.
--manifest_path MANIFEST_PATH
数据列表路径 默认: dataset/manifest.train.复制
训练模型
CUDA_VISIBLE_DEVICES=0,1 python3 train.py复制
训练输出结果如下:
----------- Configuration Arguments -----------
batch_size: 32
data_mean: -3.146301
data_std: 52.998405
dataset_vocab: dataset/zh_vocab.json
learning_rate: 0.001
num_epoch: 200
num_workers: 8
pretrained_model: None
save_model: models/
test_manifest: dataset/manifest.test
train_manifest: dataset/manifest.train
------------------------------------------------
I0303 16:55:39.645823 16572 nccl_context.cc:189] init nccl context nranks: 2 local rank: 0 gpu id: 0 ring id: 0
I0303 16:55:39.645821 16573 nccl_context.cc:189] init nccl context nranks: 2 local rank: 1 gpu id: 1 ring id: 0
W0303 16:55:39.905000 16572 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.0, Runtime API Version: 10.2
W0303 16:55:39.905090 16573 device_context.cc:362] Please NOTE: device: 1, GPU Compute Capability: 7.5, Driver API Version: 11.0, Runtime API Version: 10.2
W0303 16:55:39.907197 16572 device_context.cc:372] device: 0, cuDNN Version: 7.6.
W0303 16:55:39.907199 16573 device_context.cc:372] device: 1, cuDNN Version: 7.6.
input_size的第三个参数是变长的,这里为了能查看输出的大小变化,指定了一个值!
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv1D-1 [[32, 128, 500]] [32, 500, 324] 3,073,000
Sigmoid-1 [[32, 250, 324]] [32, 250, 324] 0
GLU-1 [[32, 500, 324]] [32, 250, 324] 0
Dropout-1 [[32, 250, 324]] [32, 250, 324] 0
ConvBlock-1 [[32, 128, 500]] [32, 250, 324] 0
Conv1D-2 [[32, 250, 288]] [32, 500, 282] 876,000
Sigmoid-2 [[32, 250, 282]] [32, 250, 282] 0
GLU-2 [[32, 500, 282]] [32, 250, 282] 0
Dropout-2 [[32, 250, 282]] [32, 250, 282] 0
ConvBlock-2 [[32, 250, 288]] [32, 250, 282] 0
Conv1D-3 [[32, 250, 282]] [32, 2000, 251] 16,004,000
Sigmoid-3 [[32, 1000, 251]] [32, 1000, 251] 0
GLU-3 [[32, 2000, 251]] [32, 1000, 251] 0
Dropout-3 [[32, 1000, 251]] [32, 1000, 251] 0
ConvBlock-3 [[32, 250, 282]] [32, 1000, 251] 0
Conv1D-4 [[32, 1000, 251]] [32, 2000, 251] 2,004,000
Sigmoid-4 [[32, 1000, 251]] [32, 1000, 251] 0
GLU-4 [[32, 2000, 251]] [32, 1000, 251] 0
Dropout-4 [[32, 1000, 251]] [32, 1000, 251] 0
ConvBlock-4 [[32, 1000, 251]] [32, 1000, 251] 0
Conv1D-5 [[32, 1000, 251]] [32, 4323, 251] 4,331,646
===========================================================================
Total params: 26,288,646
Trainable params: 26,288,646
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 7.81
Forward/backward pass size (MB): 1222.19
Params size (MB): 100.28
Estimated Total Size (MB): 1330.28
---------------------------------------------------------------------------
Epoch 0: ExponentialDecay set learning rate to 0.001.
Epoch 0: ExponentialDecay set learning rate to 0.001.
[2021-03-03 16:56:01.754491] Train epoch 0, batch 0, loss: 269.343811
[2021-03-03 16:58:08.436214] Train epoch 0, batch 100, loss: 7.195621
[2021-03-03 16:59:54.781490] Train epoch 0, batch 200, loss: 6.914866
[2021-03-03 17:01:34.841955] Train epoch 0, batch 300, loss: 6.824973
[2021-03-03 17:03:09.492905] Train epoch 0, batch 400, loss: 6.905243复制
您可以使用 python train.py --help 命令查看各个参数的说明和默认值。

usage: train.py [-h] [--batch_size BATCH_SIZE] [--num_workers NUM_WORKERS]
[--num_epoch NUM_EPOCH] [--learning_rate LEARNING_RATE]
[--data_mean DATA_MEAN] [--data_std DATA_STD]
[--train_manifest TRAIN_MANIFEST]
[--test_manifest TEST_MANIFEST]
[--dataset_vocab DATASET_VOCAB] [--save_model SAVE_MODEL]
[--pretrained_model PRETRAINED_MODEL]
optional arguments:
-h, --help show this help message and exit
--batch_size BATCH_SIZE
训练的批量大小 默认: 32.
--num_workers NUM_WORKERS
读取数据的线程数量 默认: 8.
--num_epoch NUM_EPOCH
训练的轮数 默认: 200.
--learning_rate LEARNING_RATE
初始学习率的大小 默认: 0.001.
--data_mean DATA_MEAN
数据集的均值 默认: -3.146301.
--data_std DATA_STD 数据集的标准值 默认: 52.998405.
--train_manifest TRAIN_MANIFEST
训练数据的数据列表路径 默认: dataset/manifest.train.
--test_manifest TEST_MANIFEST
测试数据的数据列表路径 默认: dataset/manifest.test.
--dataset_vocab DATASET_VOCAB
数据字典的路径 默认: dataset/zh_vocab.json.
--save_model SAVE_MODEL
模型保存的路径 默认: models/.
--pretrained_model PRETRAINED_MODEL
预训练模型的路径,当为None则不使用预训练模型 默认: None.复制
visualdl --logdir=log --host 0.0.0.0复制
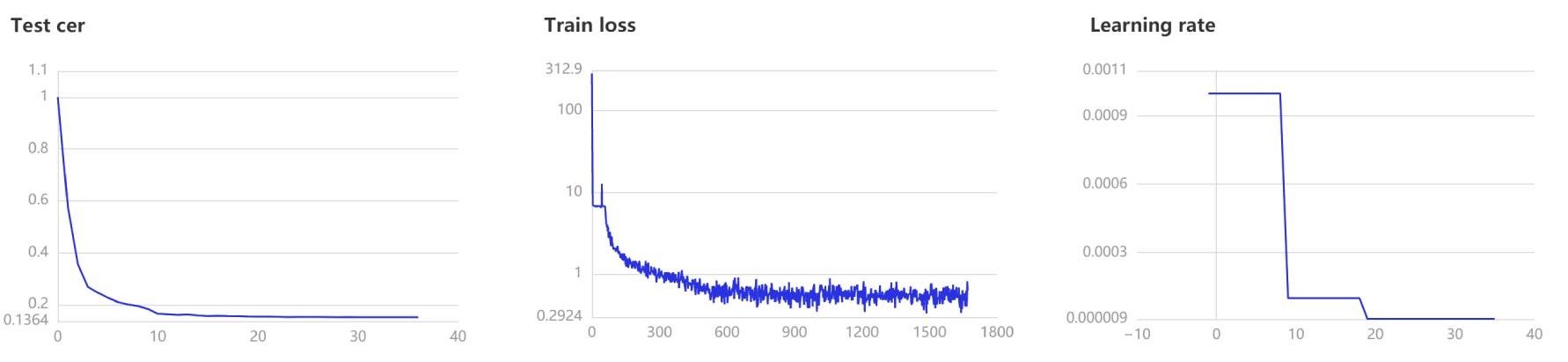
火
评估与预测
在评估和预测中,采用贪心策略解码方法对结果进行解码。 贪心策略是在每一步中选择概率头家的输出值,从而得到最终的解码输出序列。 然而学英语,CTC网络的输出序列仅对应搜索空间中的一条路径,而一个最终标签可以对应搜索空间中的N条路径。 因此,概率头家的路径不等于最终标签的概率头家,即不是头家解。 但贪心策略是最简单、最容易、最快的方法。 语音识别中最常用的解码方法是定向搜索策略。 这种策略准确率较高,但也比较复杂,解码速度也比较慢。
python3 eval.py --model_path=models/step_final/复制
您可以使用 python eval.py --help 命令查看每个参数的说明和默认值。
usage: eval.py [-h] [--batch_size BATCH_SIZE] [--num_workers NUM_WORKERS]
[--test_manifest TEST_MANIFEST] [--dataset_vocab DATASET_VOCAB]
[--model_path MODEL_PATH]
optional arguments:
-h, --help show this help message and exit
--batch_size BATCH_SIZE
训练的批量大小 默认: 32.
--num_workers NUM_WORKERS
读取数据的线程数量 默认: 8.
--test_manifest TEST_MANIFEST
测试数据的数据列表路径 默认: dataset/manifest.test.
--dataset_vocab DATASET_VOCAB
数据字典的路径 默认: dataset/zh_vocab.json.
--model_path MODEL_PATH
模型的路径 默认: models/step_final/.复制
python3 infer.py --audio_path=./dataset/test.wav复制
您可以使用 python infer.py --help 命令查看各个参数的说明和默认值。
usage: infer.py [-h] [--audio_path AUDIO_PATH] [--dataset_vocab DATASET_VOCAB]
[--model_path MODEL_PATH]
optional arguments:
-h, --help show this help message and exit
--audio_path AUDIO_PATH
用于识别的音频路径 默认: dataset/test.wav.
--dataset_vocab DATASET_VOCAB
数据字典的路径 默认: dataset/zh_vocab.json.
--model_path MODEL_PATH
模型的路径 默认: models/step_final/.复制
模型下载
数据集
错误率
下载链接
艾舍尔
0.151082
点击下载
free_st_chinese_mandarin_corpus
0.214240
点击下载
thchs30
0.081742
点击下载